搜索引擎技术
搜索引擎的基本术语
查询词(query)

查询建议(SUG)
SUG的作用是让搜索引擎用起来更方便
搜索结果页
通常把搜索结果称为文档,这些文档可以是网页链接、视频等

标签/筛选项
文档曝光
文档曝光主要是产品形态的区别,并不能代表后台的搜索引擎算法和工程架构

再解释一下曝光,即只要用户在搜索结果页上看到文档,就算曝光。
点击率
搜索引擎一般考虑两类点击率:文档点击率、查询词点击率
文档点击率

查询词点击率(又称有点比)

对比

文档点击率、有点比、首屏有点比这三种指标的关联性很强,一个指标提升通常来说其他两个指标也会提升,但并不是绝对的。改进排序策略通常会同时提升三种指标,改进召回策略可以提升文档点击率和有点比(但很难提示首屏有点比,因为首屏的几篇文档主要由排序决定,召回起到的作用很小)
垂直搜索(垂搜)

通用搜索(通搜)

值得关注的是抖音、快手、小红书这样的平台,使用都是通用搜索
AB测试(A/B测试)

实验推全

用户满意度

holdout
指的是留出法(Holdout Method),这是==一种简单的模型评估方法==。具体来说,留出法是将数据集随机划分为两个互斥的子集:训练集和测试集。==训练集用于模型的训练,而测试集用于评估模型的泛化能力==。这种方法的基本思想是用训练集来拟合模型,然后用测试集来评估模型的性能
工业界

这个概念一般和学术界对应,也就是我们常说的:实战环境、实际场景、实际工作场景等
BERT模型


用户满意度
相关性
相关性定义

相关性在实战环境下的用途

内容质量
EAT
EAT是一种指标。并且注意,虽然EAT是专业性(Expertise)、权威性(Authoritativeness)、可信赖(Trustworthiness)三个单词的首字母缩写,但是在业界一般直接以
权威性称呼

此外在对一些特定主题(一些严肃且重要的主题),搜索引擎排序应该给予EAT分数很高的权重,这些特定的主题在英文术语里被称为your money or your life,具体如下

举个例子,你搜国家政策,搜索引擎就应该把相关政府网站排在最前面,而不是一些民间机构或组织的站点,不然搜索结果就乱套了,从而会引发社会问题。
文本质量
EAT针对的是作者和网站,而文本质量针对的是文档本身


这里提一点,标题党、图文不一致、虚假引流标签、堆砌关键词等方法,都是为了欺骗搜索引擎以吸引到流量,这些都是负向的信号,这样的文档应当被判定为低质量而被搜索引擎打压。
文本质量还有几个关键的点,如下:

训练模型的数据是人工标注的,比如先将文本质量分成高、中、低三个档位,然后让人工做标注,给每篇文章一个档位(类似于老师批作文)。有数据之后就可以训练模型了,通常来说模型要先做预训练,然后再用人工标注的模型做翻训,人工标注的数据可多可少(几万或者十几万的数据也能把模型训练好)。
图片质量(视频质量)
除了文本质量,有些搜索引擎还会用到图片质量(视频质量)

还是再强调一下,内容质量不是一个分数而是很多分数,比如上面提到的EAT、文字质量、文章意图、图文一致性等等各自都是一个分数,在搜索排序阶段会使用所有内容质量分数,让质量高的文档更容易排在前面。
时效性

==文档的时效性在排序中起的作用取决于查询词==,查询词对时效的需求越强,那么文档年龄的权重就越大

此外还要注意,查询词有很多种意图,包括时效性意图、地域性意图等
突发时效性

这里说一下,对于抖音、小红书、微博等平台,可以挖掘站内发布量激增的关键词,如果某个关键词的数量激增,则一定是发生了相关的事件,系统会判定这个关键词带有突发失效性。
再思考一个问题,为什么要采用数据挖掘的识别方法,而不是使用自然语言模型(路BERT、GPT等)?

对于突发时效性这个问题,人判断不好,模型同样判断不好。所以不能用模型,只能通过数据挖掘来判断突发时效性。
一般时效性

这里要注意,每家公司都有自己的分档标准,用来指导标注员标数据。也可以看到,对于一般时效性,用模型也能判断好,而不需要使用数据挖掘
周期时效性

虽然可以不对周期时效性进行处理(识别),但是如果不识别周期时效性,速度可能会慢半拍,还有可能被算法遗漏掉。
个性化
搜索引擎的个性化类似于推荐系统(可以做到千人千面)。==在移动端的APP,搜索引擎一般都带有个性化,因为移动端的APP用户一般都会登录,那么APP可以记录用户历史上的行为,从而知道用户的偏好,在排序的时候,搜索引擎会根据用户的偏好,让结果带有个性化==。

这里详细讲讲搜索引擎是怎么做到个性化的:搜索排序阶段,会使用模型预估点击率和交互率,用预估值来衡量用户对文档的偏好,预估点击率和交互率的模型与推荐系统的几乎一模一样,推荐系统排序所用到的技术在搜索引擎中也几乎全都适用。预估点击率和交互率的值越大说明用户对文档越感兴趣。

总之不管做不做个性化,搜索排序都会预估点击率和交互率
搜索引擎的评价指标
想要让搜索引擎变得更好,首先就要定义什么是更好

需要注意的是,对于某些垂类搜索引擎来说北极星指标会有所区别,比如电商搜索引擎可能还会增加商品交易总额这项。
==直接提升北极星指标难度是比较大的,所以搜索引擎会用一些中间指标来牵引技术和产品的迭代优化,中间指标相比北极星指标更容易提升,并且和北极星正相关==。
北极星指标:用户规模&用户留存
北极星指标又称核心指标。
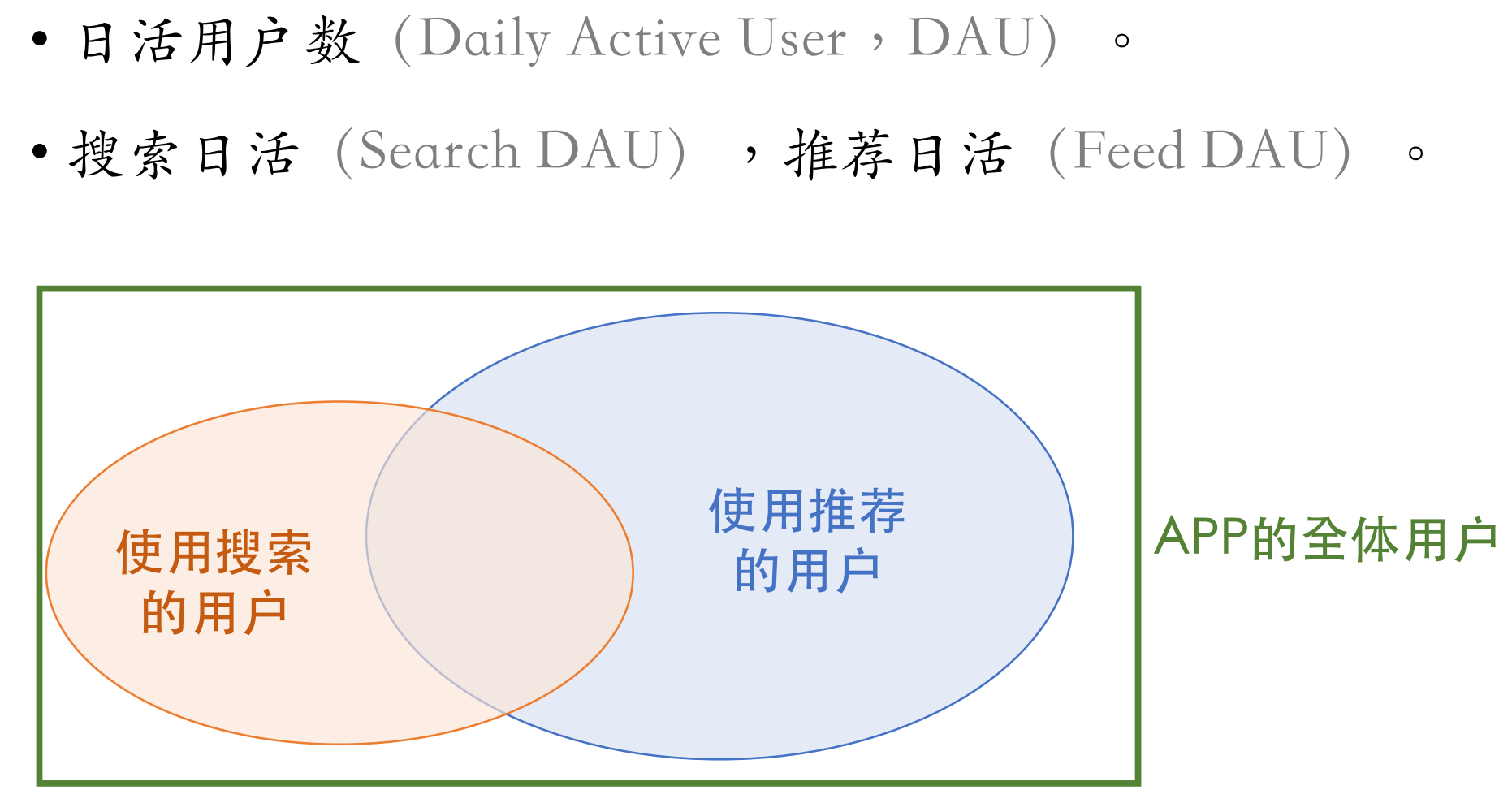
用户规模
用户规模主要以日活用户数来衡量(也可以月活用户数)。
像百度、抖音、小红书、淘宝等应用,既有搜索又有推荐(即用户规模的增长可能不是搜索带来而是推荐带来的),这种情况下需要把单独的功能拿出来考察,分别看搜索日活和推荐日活。
除了上面说到的日活用户数、搜索日活、推荐日活等指标,还有一些其他的指标,如下

用户留存
次n留

如果一个APP有多个功能,可以把每个功能单独拆出来看留存指标,即APP次n留、搜索次n留、推荐次n留
举一个次7留的例子,如下

中间指标:点击等行为
中间指标主要基于用户的点击行为,很容易在A/B测试中反映出来。
首点位置

首点位置和首屏有点比其实是一个道理,都能反映搜索排序做到好不好。
主动换词率
主动换词率高是一件坏事。


交互指标

为什么更关注中间指标而不是北极星指标?



人工体验评估
人工评估其实存在很多确定,所以争议比较大。

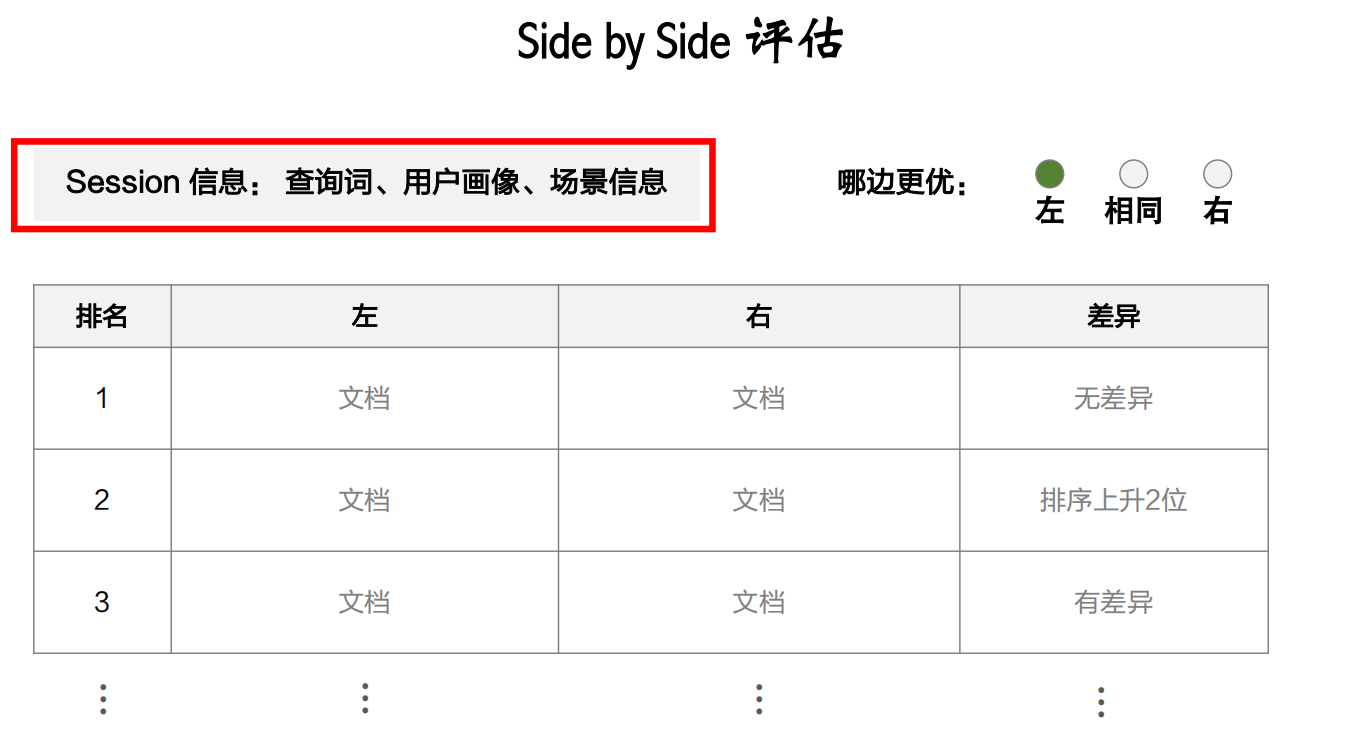
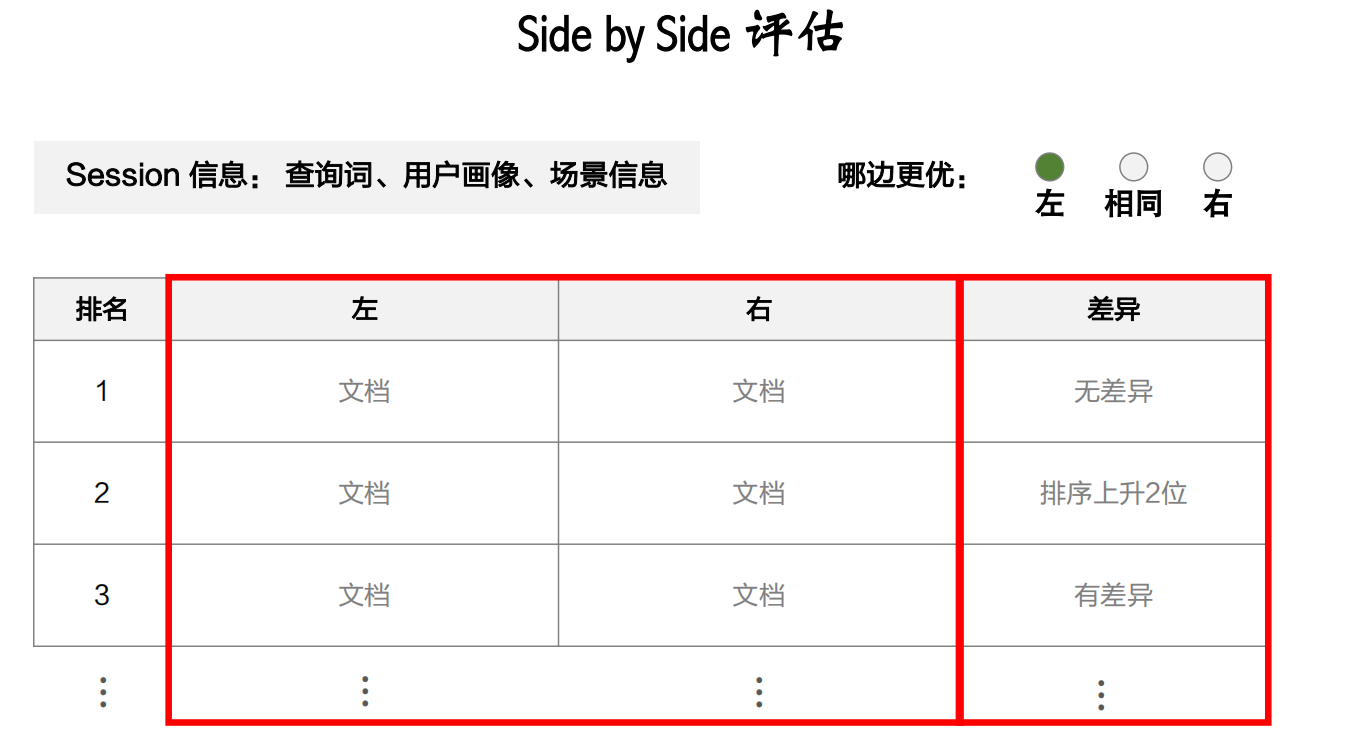
Side by Side评估
目前(2024.5.11),百度使用是Side by Side评估,而小红书这类强个性化的搜索引擎不使用也不适用这套评估

场景包括时间、地点、手机型号等信息

盲评,指的是标注员并不知道哪个是新策略哪个是旧策略,这样就不会受到主观因素的影响

下面再展示一下标注员看到的界面信息,类似下图:
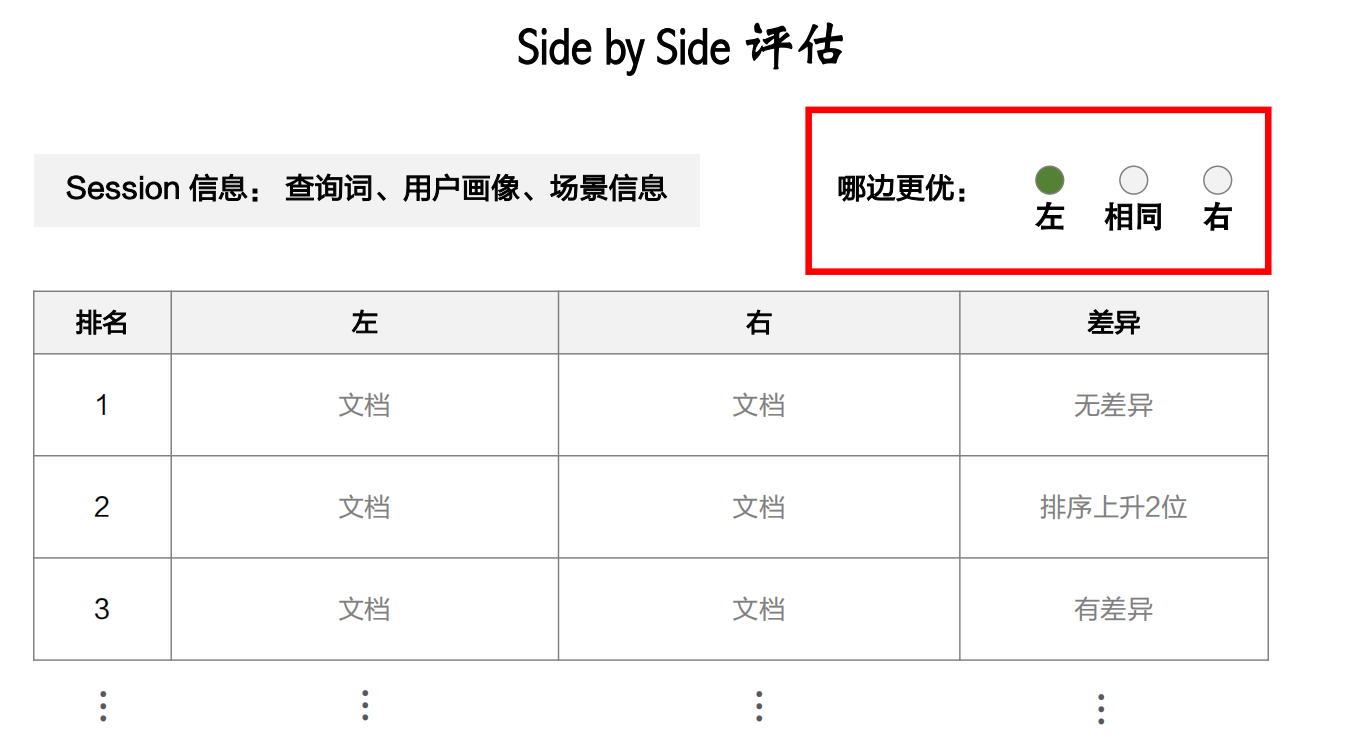
月度评估



搜索结果越好DCG就越大,==一个DCG分数是对一个搜索结果页整体的评价==,所以后面要取均值来作为月度评估的结果。
自我对比,公司可以用DCG分数来考察搜索团队有没有让用户体验变好。
竟对对比,就是和竞争对手做对比。
Side by Side评估和月度评估的对比

搜索引擎的链路
先看一下搜索引擎的链路图,如下:
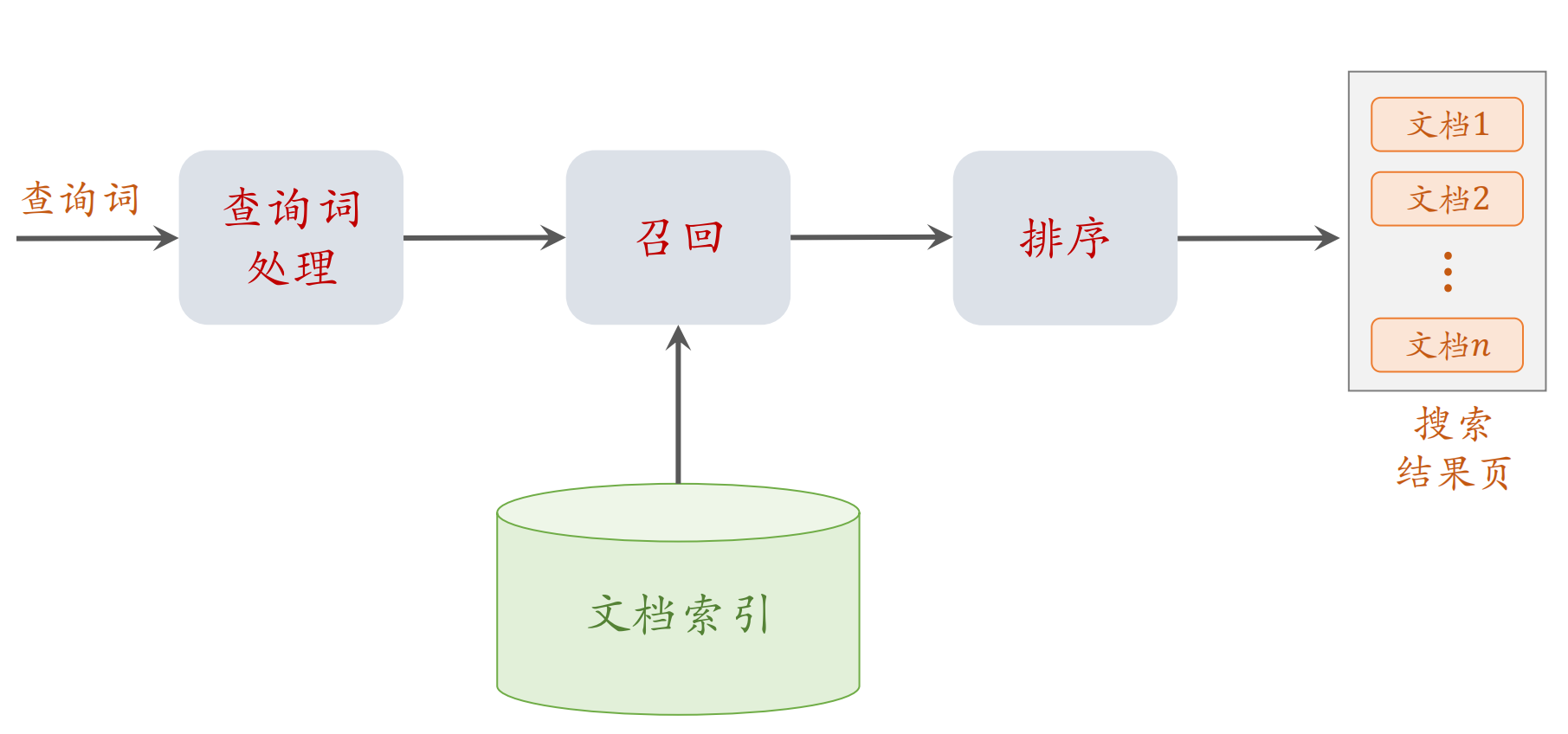
查询词处理
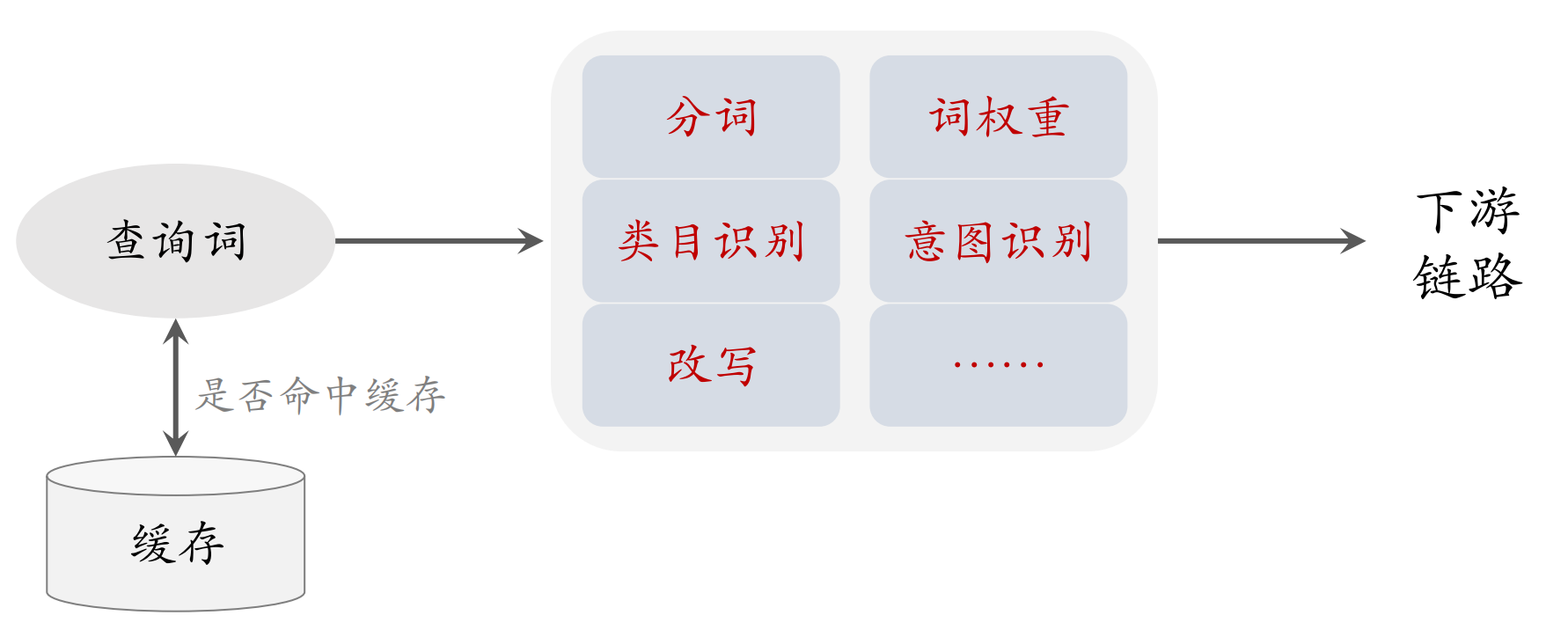
查询词处理的重要性其实不高,只要有分词就可以做文本召回,搜索引擎就能勉强工作了(如果用向量召回甚至连分词都不需要)。词权重、类目识别、意图识别、改写这些功能都是为了让搜索引擎效果更好,而不是必不可少的。
下面介绍查询词处理中的几个模块。
分词
对于中文搜索引擎,查询中必不可少的模块就是分词

词权重
词权重不是必要的,但是对搜索引擎很有用


类目识别
一个平台大约有几十个一级类目,几百个二级类目,甚至还会细分出三级类目

意图识别

注意,这里只是列举出了四种查询词意图,其实还有很多其他意图。并且一条查询还可以带有多种意图。
改写


召回(Retrieval)
召回通道不是一条,一般有二三十条,每条召回通道都有自己的配额(比如召回1000条数据、召回3000条数据等)。文本召回和向量召回是搜索引擎最重要的召回通道,当然,还会有一些其他的召回通道作为补充。
召回的量一般很大(大约有几万篇文档),在做初步筛选后,会传递给排序(大约传递几千篇文档)。

文本召回
文本召回就是最简单的文本匹配,文本召回是最传统的搜索引擎技术,在深度学习成熟之前搜索引擎几乎只有文本召回。

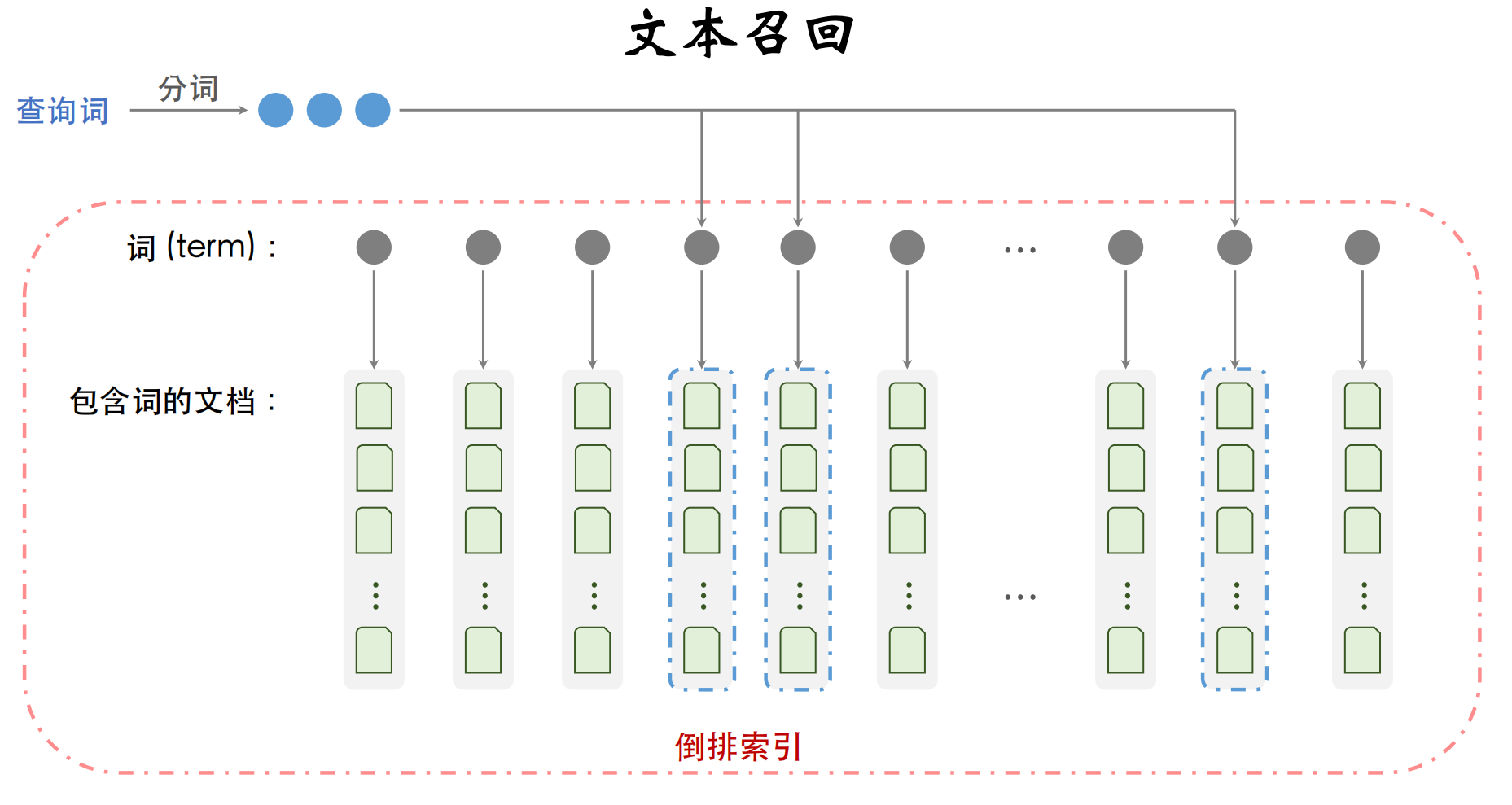
这里简单讲一下倒排索引,如下


在倒排索引中,有一个概念叫term(词项),具体如下
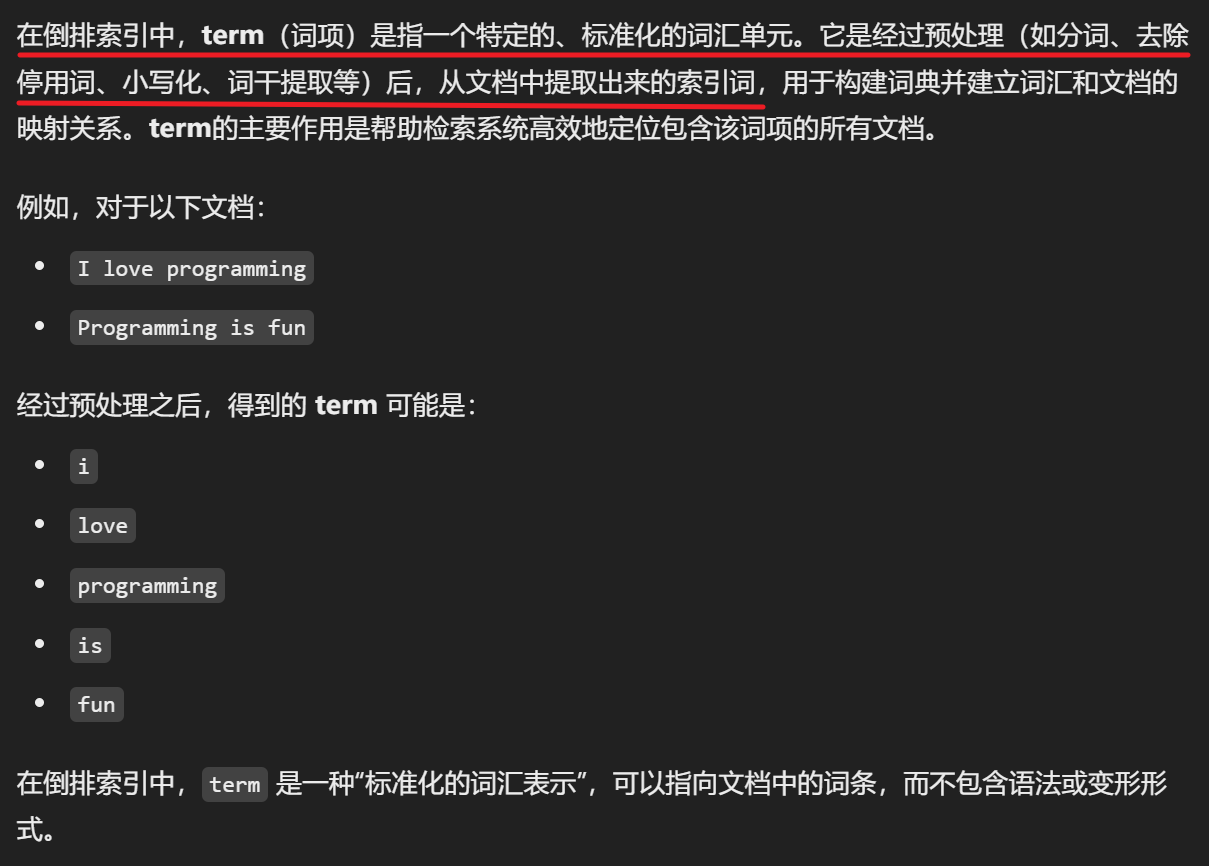
下面用一个示意图加深文本召回的理解:
向量召回
最近几年(2024.5.11)向量召回的重要性已经超过文本召回。
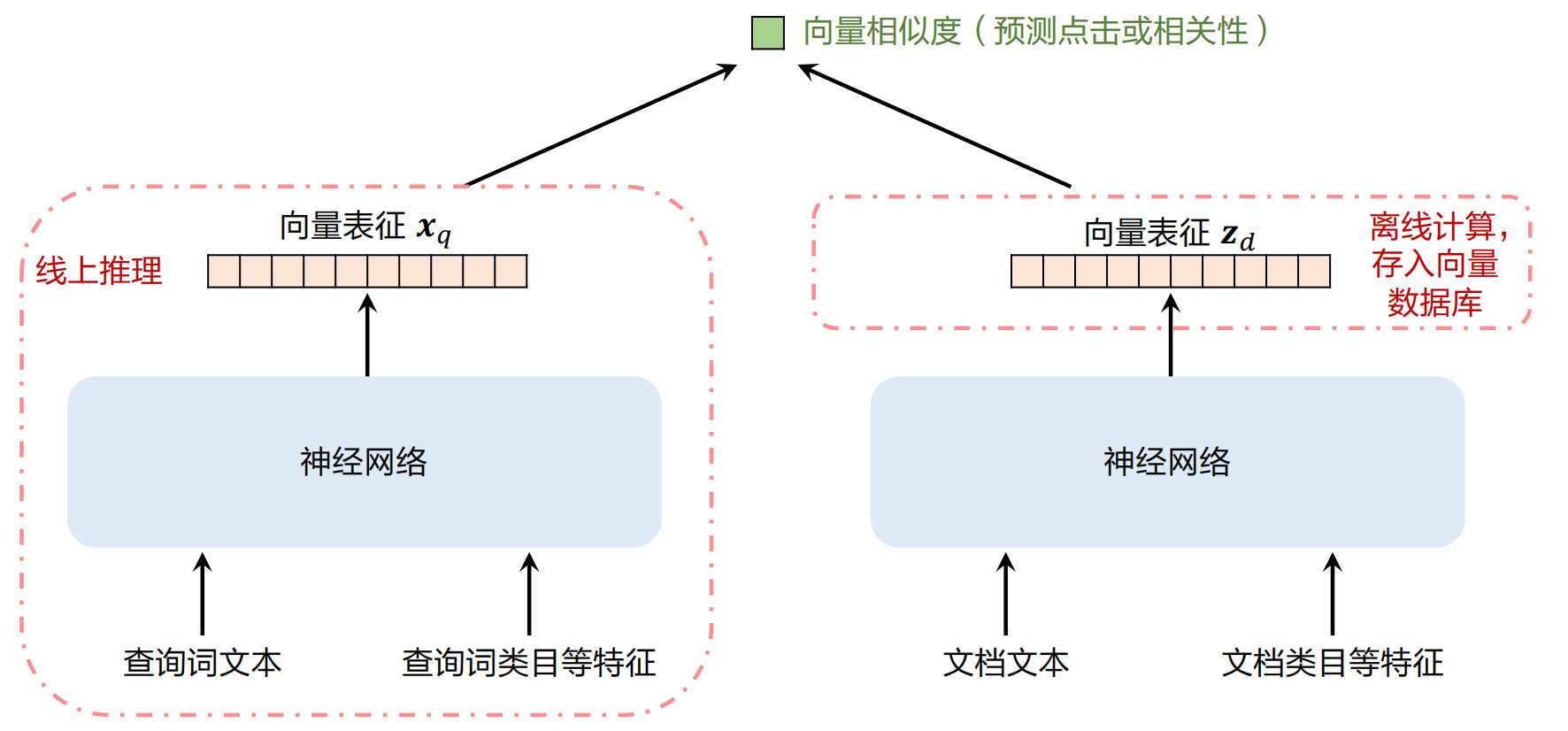
如上示意图,使用的就是双塔模型,主要就是通过向量相似度来进行查找从而实现召回
简单介绍一下双塔模型,如下:


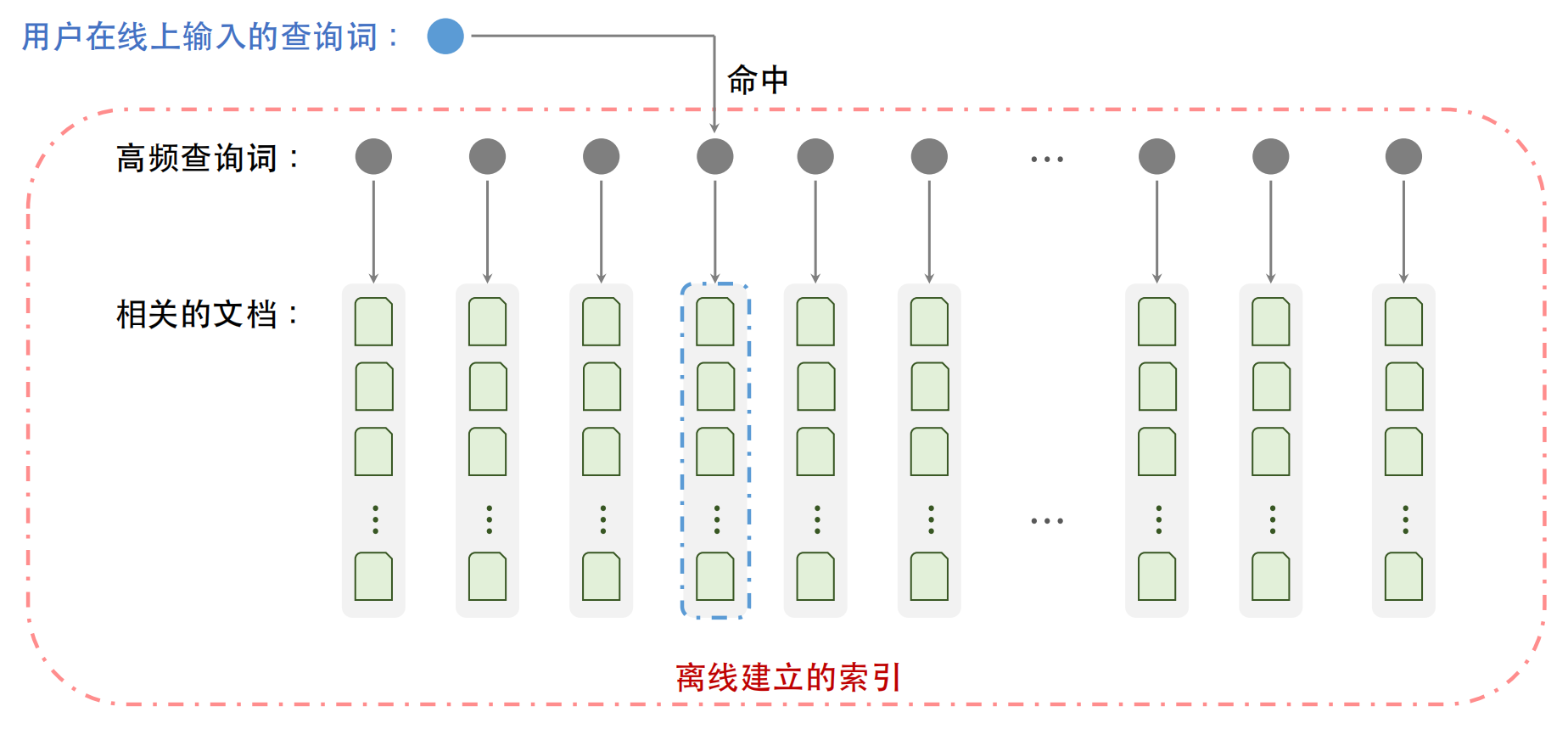
KV召回
KV召回的基本逻辑就是先建立一个离线的索引(可以拿来直接用的那种),然后使用这个索引完成召回。
KV召回中的K指的是高频查询词(来源于用户真实搜过的查询词,在过去某段时间搜索次数高于某个阈值时就会被收录),V指的是文档列表。由于这个离线的索引已经做过筛选,所以这个索引中的K和V具有高相关性,当用户检索的查询词是个高频查询词就会命中索引,该查询词下对应的文档就会被召回。
KV召回的效率很高,且召回的文档几乎都和查询词具有高相关性。
排序(Ranking)
排序有可能会分为粗排和精排两阶段,原理基本相同,区别只是用的模型不同。
搜索排序需要用多个模型计算多种分数,具体有以下几点:

相关性是最重要且消耗算力最多的,可以说搜索排序大半的算力都花在了相关性上。
对于相关性的计算,使用多大的模型取决于算力有多充足,每家公司都不一样(4层、6层、12层的都有)。
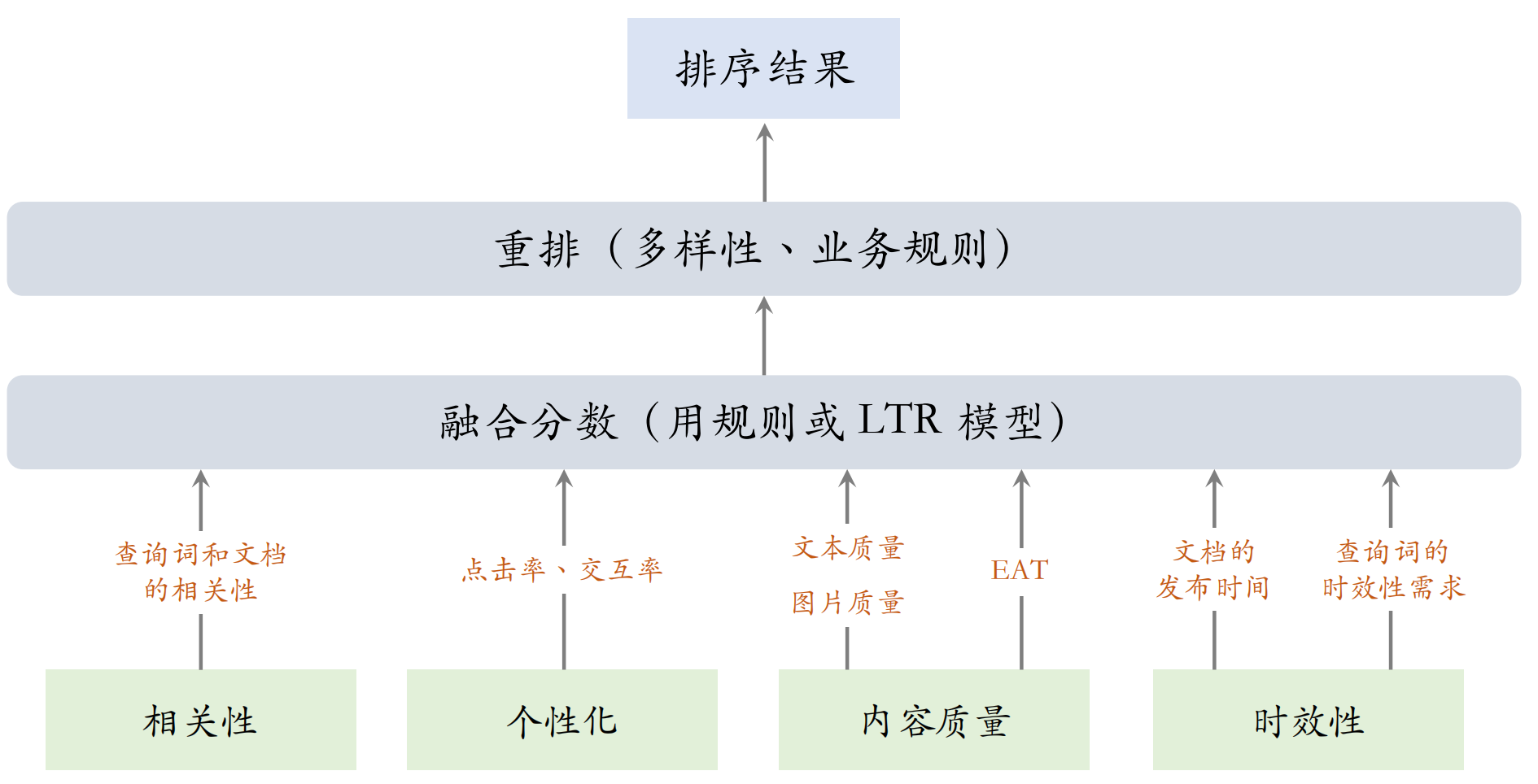
下面用一幅图对搜索排序的原理做一个说明:
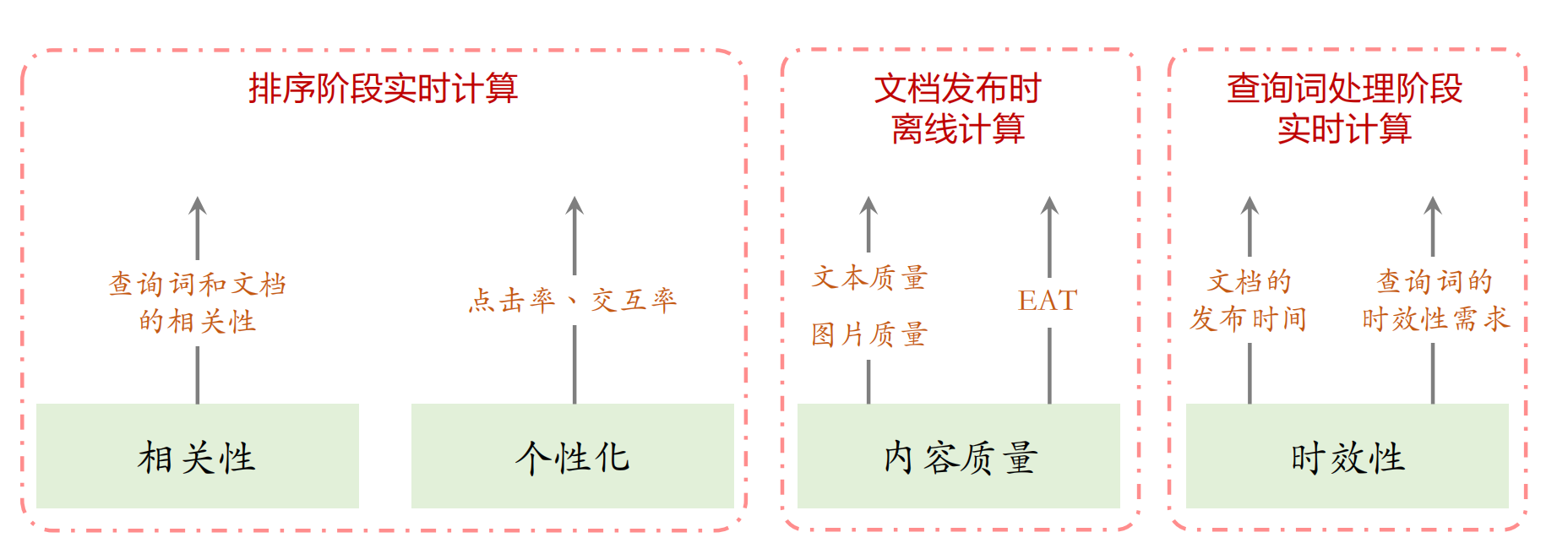
这里提一点,内容质量是在文档发布的时候用不同的模型和规则计算出来的,存储在文档的画像中
搜索排序的第一个阶段就是打分,即计算或收集相关性、个性化、内容质量、时效性等分数,得到分数后进行融合,融合可以使用规则或LTR模型,==融合得到的分数基本上决定了搜索结果页上文档的排序==,得到融合分数后还会对文档的顺序做小幅的调整(即重排),最后展示搜索排序的结果。